In this post I’d like to describe the approach to structuring product code that I’ve personally used since the early 2000’s and which I rolled out to the Orion Health Enterprise team while I was Product Architect for that product.
This model is a good fit for microservices where it helps to pragmatically answer some questions about sharing reusable code that teams new to microservices often face. It can also be adapted to monolithic code that you want to modularize ultimately into microservices.
Back at Orion I called this structure the “Product Taxonomy” which was always a clunky name. These days I refer to it as OPMC (which is marginally better) from the concepts of org-product-module-component.
Concepts
Component
Starting at the most fundamental unit, we have components.

A component is an physical unit of software such as:
- Libraries compiled to a NPM package, JAR file, DLL, etc
- Daemons that provide some service API
- Batch jobs
- Event consumers
Module
Modules are the central unit of organization in the OPMC model. Every component lives inside a module, and no component lives outside a module. If you need to build something that doesn’t fit inside an existing module, then you must identify a new module for it to belong to.
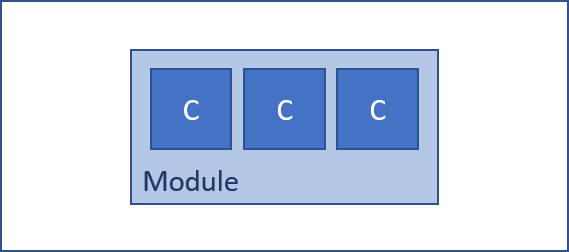
Modules are best defined using the principles of Domain Driven Design - they should enclose entities that have high affinity to each other and form some clearly bounded context. Note the important implication here that a bounded context may be implemented across multiple physical components because a module can contain multiple components.
Modules are also the unit of source control, build and versioning (see below for elaboration on this).
Product
Products are logical groupings of modules.
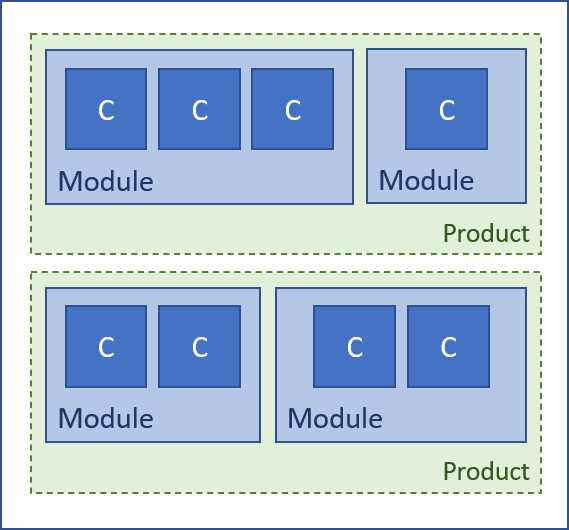
Products give our modules a common umbrella name that they can live under. Products are not otherwise expressed physically - modules are still the unit of organization, build and versioning.
Organization
The last concept is the organization which owns the software being built. The org gives a top-level namespace for our naming.
Naming
For each of the above concepts (component, module, product, organization) we define:
- Symbol - a naming element that can be used in code
- Title - a human-friendly name that can be used in documentation.
For various purposes we need qualified module and component names both with and without version numbers.
Qualified module names are composed from symbols as follows:
${organization}-${product}-${module}
Similarly for qualified component names:
${organization}-${product}-${module}-${component}
Since it is components that are turned into physical artifacts, we also need version-qualified component names:
${organization}-${product}-${module}-${component}-${version}
You can use whatever versioning approach you prefer here. I’ll share some ideas on versioning in a later post.
Update 2019-10-23: see my new post on my approach to versioning
As an example lets say we have a company “Acme Developments Pte Ltd” that is building an order management system called “Road Runner” that provides customer, stock and order functionality. We might expect to see modules like:
- acme-roadrunner-customer
- acme-roadrunner-stock
- acme-roadrunner-order
And in the customer module might contain components like:
- acme-roadrunner-customer-restapi
- acme-roadrunner-customer-repo
- acme-roadrunner-customer-database
- acme-roadrunner-customer-salesforcesyncjob
Some artifacts we might see from this product are:
- acme-roadrunner-customer-repo-1.0.483.738.jar
- Docker image:
acme/acme-roadrunner-customer-restapi:1.0.483.738
Continuous Integration Structure
Each module gets exactly one repository in our VCS, and that repository is named using the qualified module name from above.
In our Acme example above, each of the three modules would have their own Git repository and a developer from the team owning that module would get the code with something like:
git clone me@git.acme.com:/repos/acme-roadrunner-customer.git
Each module has a build script that allows it to be built from the root, and each build run applies the same version number to all components in the module.
The continuous integration system should trigger a build for the module upon any commit. For each commit to a module all components in the module are rebuilt and tested, including functional integration tests that span components in the module.
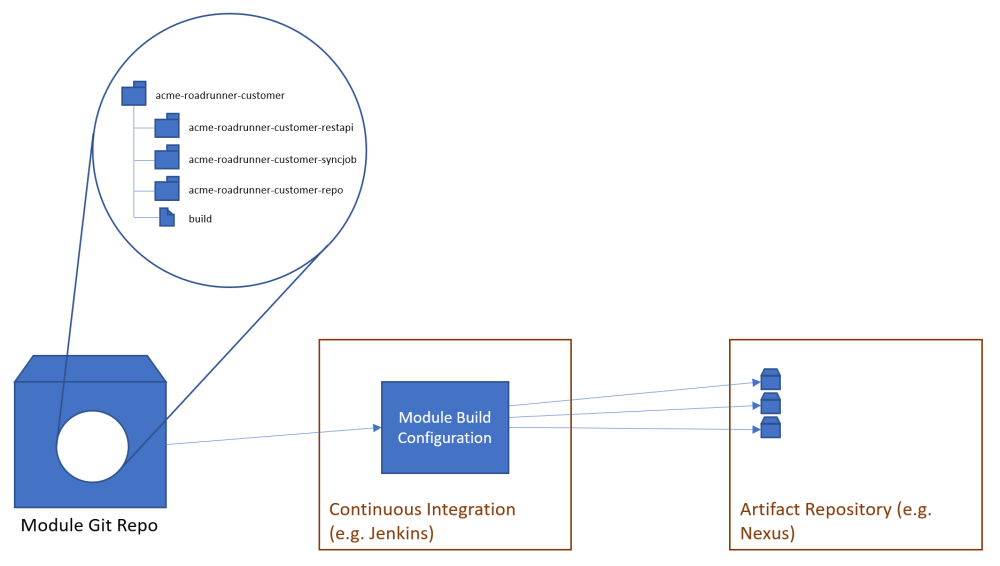
Integration tests that span into other modules should be handled separately outside the scope of the module’s CI.
Some will definitely baulk at the idea that changing one component in a module necessitates a rebuild and redeploy of all components from the module. The argument in favor of this approach is that the components within the module work on the same bounded context and likely have tight coupling between them so it’s usually unreasonable to expect you can deploy one and not the other. If you have components in a module that can easily be deployed separately then this probably means you should be splitting those into multiple independent modules.
Application to Microservices
Some teams regard microservices as the unit of organization and orient themselves around microservices, but this can easily be too granular.
The module concept is a more pragmatic level to organize teams at - a team owns and is responsible for a module, and that module may expose zero or more microservices.
Sharing common code between closely related components is also aided by having the module level in the architecture - within a module you can have a component which is a shared library that is integrated by multiple other component’s in the same module.
For example in the Acme scenario above the salesforcesyncjob and the restapi components could both use the repo library component to talk to the database.
Application to Monoliths
A good way to start breaking up a monolith is to modularize-in-place - meaning reorganizing code within your monorepo to define those modules that will later be sliced out and moved to their own repositories. OPC can be adapted to permit this by relaxing the one-to-one relationship between module and VCS repo.
From my experience adopting this approach to break up a monolith - it works but it takes time and really requires commitment from the business to enable it to happen - make sure you have plenty of both before you start down this path, otherwise it might be better to stay with the monolith.
Conclusion
The OPMC model provides a simple and pragmatic pattern for organizing your code that is aligned with the principles of DDD and is a good fit for organizing microservice-based product suites.